Generative World Models
Action-conditioned, multi-view video models for controllable, reproducible, long-horizon simulation.
I build generative models that imagine how the physical world may unfold, then use those imagined futures to help intelligent agents reason and act.
My research began with 3D perception: point-cloud tracking, segmentation, occupancy, and geometry-aware representations. Today, I focus on action-conditioned world models, causal video generation, VLA systems, and closed-loop simulation.
I was the first author and a core contributor to X-World. Alongside hands-on research, I define problems, design experiments, and mentor early-career researchers across both product and academic projects.
Action-conditioned, multi-view video models for controllable, reproducible, long-horizon simulation.
Multimodal action decoding, latent future reasoning, and reinforcement-learning post-training.
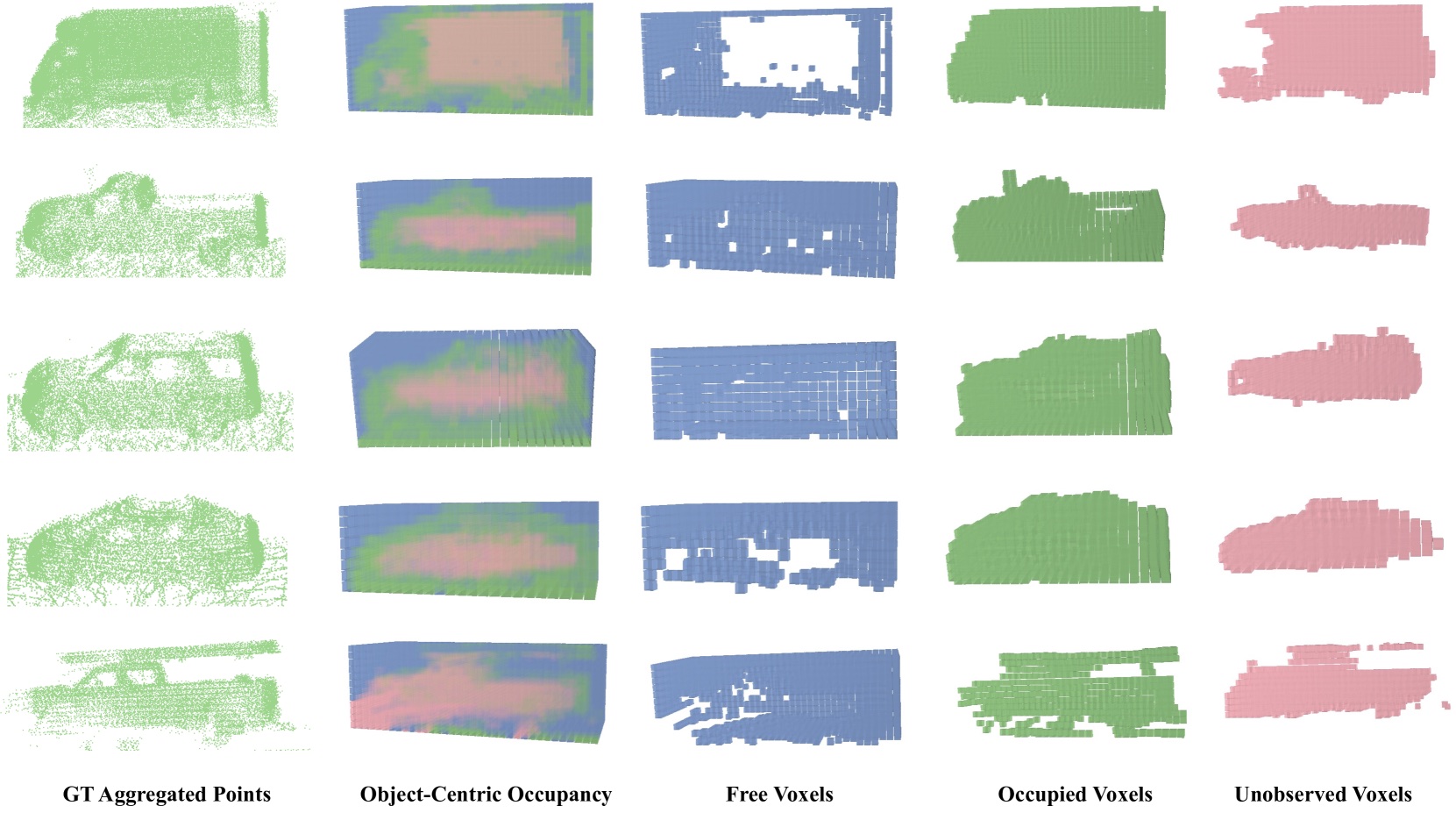
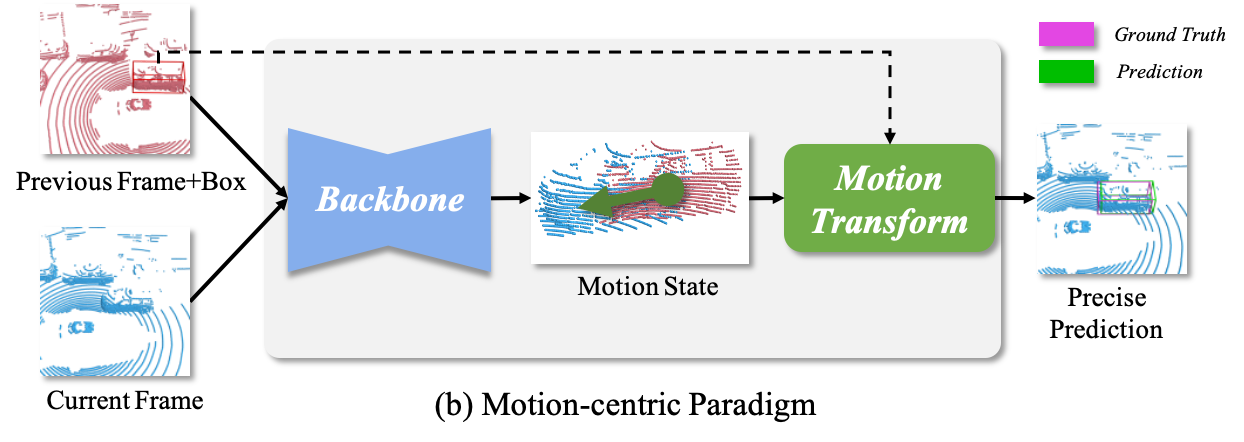
Object-centric occupancy, point-cloud tracking, segmentation, and geometry-aware representation.
Efficient autoregressive inference, sequence parallelism, and high-throughput closed-loop evaluation.
A seven-camera action-conditioned world model for stable 30+ second generation and VLA closed-loop evaluation. I led causalization, few-step distillation, long-horizon post-training, and the first simulation inference pipeline.
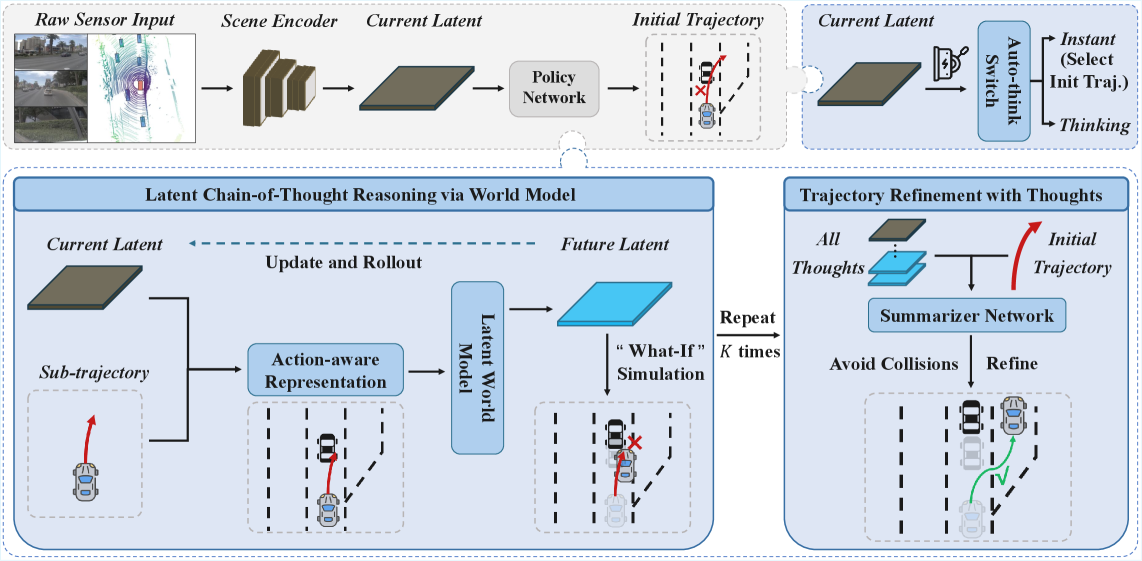
An end-to-end driving policy that reasons through possible futures in latent space before choosing an action.
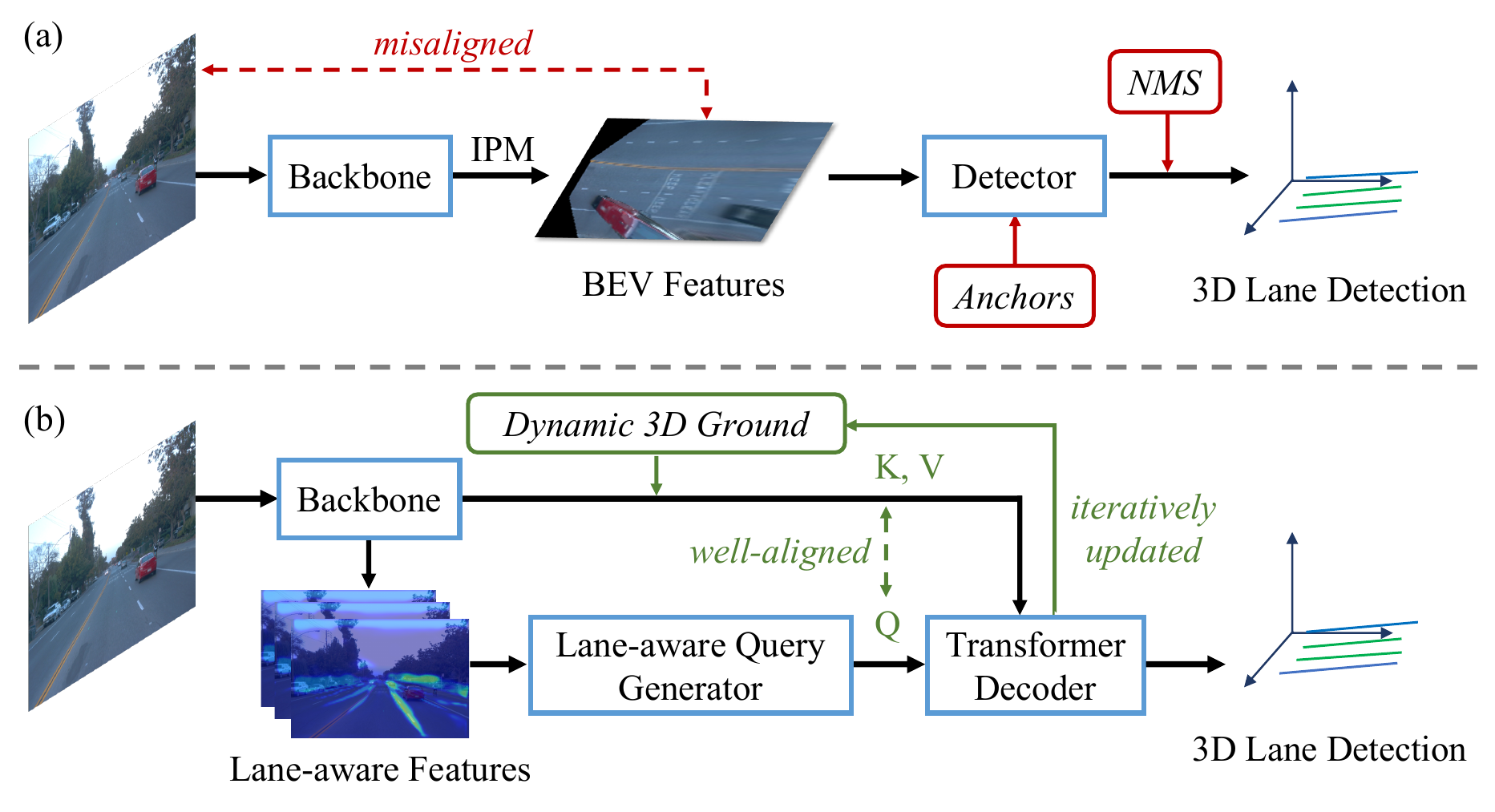
Transformer-based 3D lane detection from monocular images, bridging image features and lane geometry in 3D space.
Area Chair
Reviewer
CVPR · ICCV · ECCV · NeurIPS